Created by Mark Davies.
Funded by the US National Endowment for the Humanities
(2001-2002, 2015-2017).
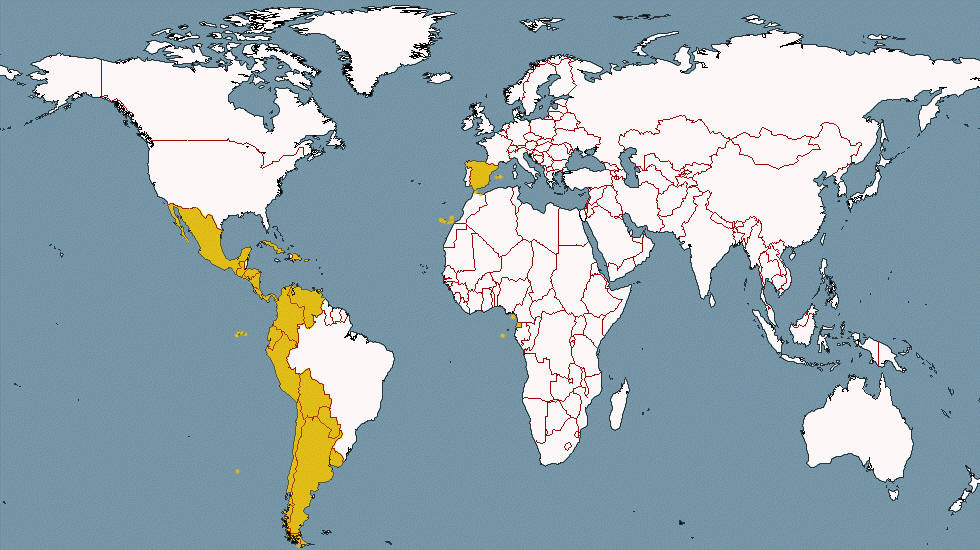
This is the newest addition to the Corpus del Español. It contains
more than 7.3 billion words from 21 different Spanish-speaking
countries, from 2012 through 2019.
|
|