Creado por Mark Davies.
Subvencionado por el programa National Endowment for the Humanities de Estados Unidos (2001-2002, 2015-2017).
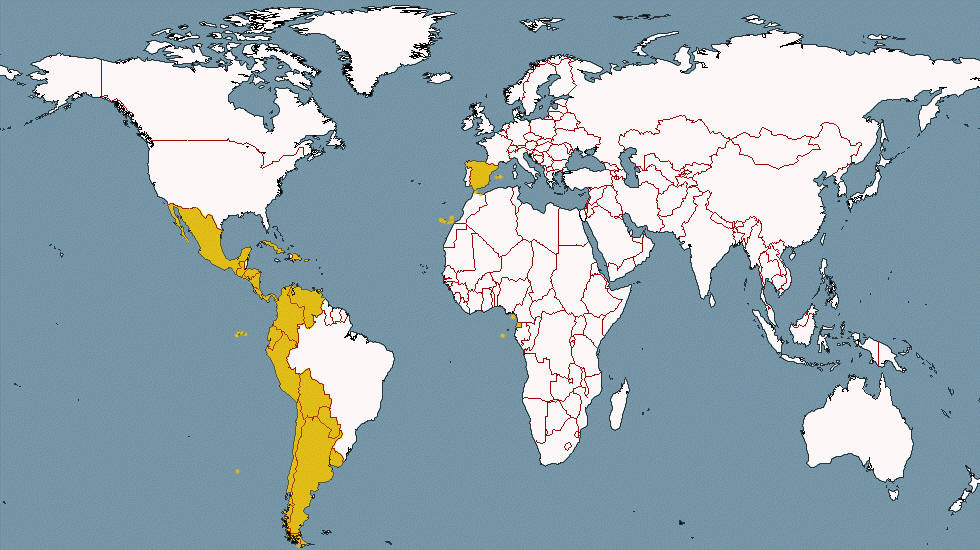
La adición al Corpus del Español (2016) contiene casi dos mil millones de palabras de páginas web de 21 diferentes países de habla hispana.
Este corpus permite hacer búsquedas en textos en español muy recientes (los textos se recopilaron en 2013 y 2014) y comparar los diferentes dialectos.
El nuevo corpus es además mucho más grande que el anterior, más de cien veces más grande para el español actual (2.000 millones de palabras, en comparación con los 20 millones de la sección del siglo XX del corpus original). De este modo, búsquedas que podrían obtener 10-12 resultados en el corpus original, pueden obtener 1000 o más en el nuevo corpus.
En 2022, agregamos muchas funciones nuevas a este corpus: 1) navegación y
búsqueda en los 40 000 lemas principales en el corpus 2) "páginas de palabras"
detalladas con información sobre cada una de estas 40 000 palabras, inclusive
definiciones, sinónimos, enlaces a imágenes y videos , información de frecuencia
(por género y país), colocaciones, temas relacionados y líneas de concordancia),
3) la capacidad de ingresar y analizar textos completos, encontrar palabras
clave en estos textos y luego ver información detallada (#2) para cada palabra,
así como la capacidad de resaltar frases en su texto y encontrar frases
relacionadas en el corpus, y 4) enlaces extensos a recursos externos en las
pantallas de frecuencia y concordancia.
|