Creado por Mark Davies.
Subvencionado por el programa National Endowment for the Humanities de Estados Unidos (2001-2002, 2015-2017).
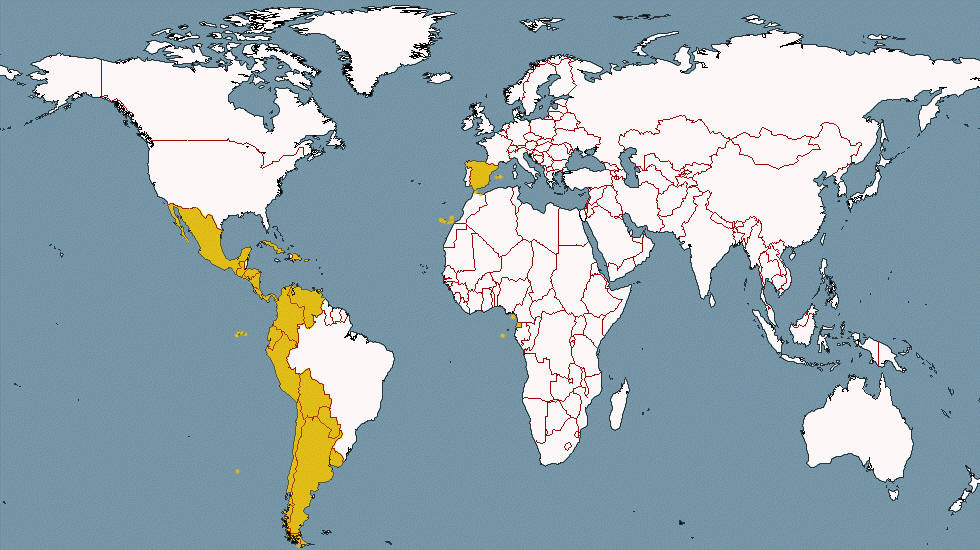
Esta es la adición más reciente al Corpus del Español. Contiene más de 7,3 mil miillones de palabras de 21 diferentes países de habla
hispana, desde 2012 hasta 2019.
|
|